Real Estate News – Recent Articles

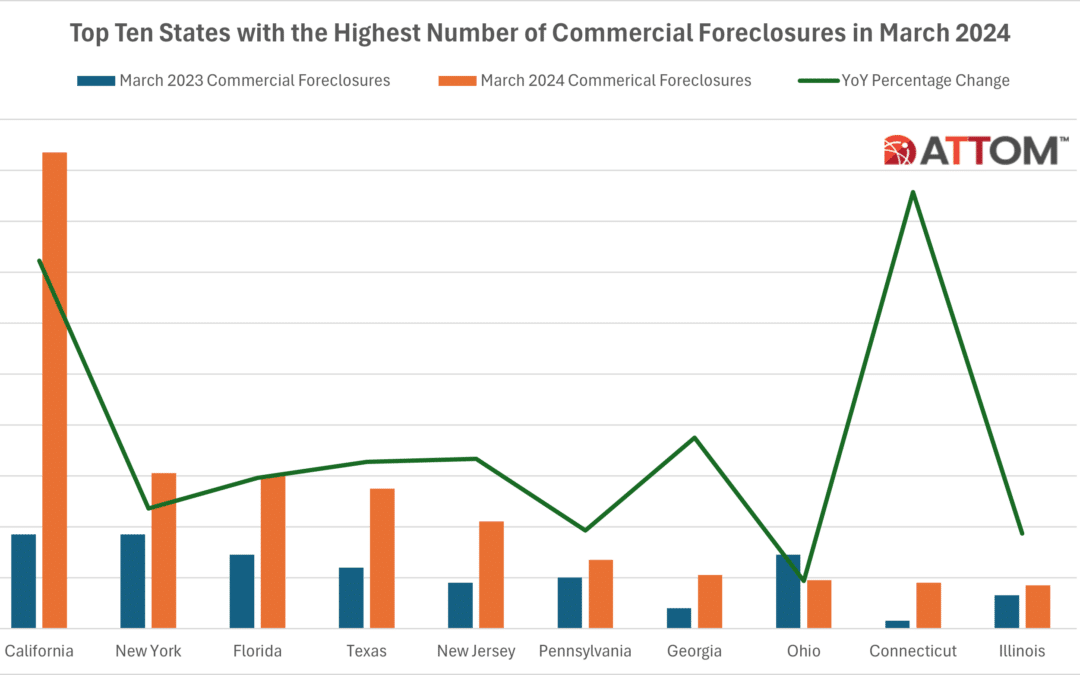
U.S. Commercial Foreclosures Increase in March 2024
Commercial Foreclosures Increased 6 Percent from Last Month and 117 Percent from Last Year; States with the Most Commercial Foreclosures in March 2024 Included California, New York and Florida IRVINE, Calif. — April 17, 2024 — ATTOM, a leading curator of land, property, and real estate data, today released an updated monthly report on U.S.... Read More »

The Benefits of Pre-Populated Customer Forms for Insurers
With so much competition across the insurance markets, insurers need to find new ways to help draw in new customers and improve the experience of existing ones — from providing the most competitive rates to offering additional benefits. Another way insurers can help convert more prospects and improve customer satisfaction rates is by offering the... Read More »
Top 10 ZIPS with Highest Foreclosure Rates in Q1 and March 2024
According to ATTOM’s newly released Q4 and March 2024 U.S. Foreclosure Market Report, there were a total of 95,349 U.S. properties with foreclosure filings in the first quarter. That figure was up 3 percent from the previous quarter but down less than 1 percent from a year ago. ATTOM’s latest foreclosure activity analysis reported that nationwide... Read More »
U.S. Foreclosure Activity Increases Quarterly in Q1 2024
Foreclosure Starts See Quarterly Increase of 2 Percent; Bank Repossessions Up 7 Percent from Previous Quarter IRVINE, Calif. — April 11, 2024 — ATTOM, a leading curator of land, property, and real estate data, today released its Q1 2024 U.S. Foreclosure Market Report, which shows a total of 95,349 U.S. properties with a foreclosure filing during... Read More »

Unveiling ATTOM’s Propensity to Default Score: Navigating Mortgage Foreclosure Risks
With February home foreclosure activity up 8% vs. a year ago, understanding a borrower’s willingness and ability to stay current on their mortgage and out of default becomes even more critical for mortgage lenders. While total foreclosures remain low by historic standards – 2023 saw 357,062 total foreclosure filings or 0.26% of all US housing... Read More »
Top 10 U.S. Counties with Highest Effective Property Tax Rates in 2023
According to ATTOM’s 2023 Property Tax Analysis for 89.4 million U.S. single family homes, there was a 6.9% surge in single-family home property taxes in 2023, reaching $363.3 billion. The report states that this is nearly double the 3.6 percent growth rate of 2022 and represents the largest increase in the past five years. ATTOM’s latest... Read More »Popular Posts
-
 U.S. Foreclosure Activity Increases Quarterly in Q1 2024
U.S. Foreclosure Activity Increases Quarterly in Q1 2024
-
Home Flipping Plummets Across U.S. in 2023 as Profits Slump Again
-
Property Taxes on Single-Family Homes Up 7 Percent Across U.S. in 2023, to $363 Billion
-
Top 10 U.S. Counties with Highest Effective Property Tax Rates in 2023
-
U.S. Foreclosure Activity Continues to See an Annual Increase




